PerAct
A Transformer for Detecting Actions
PerAct is a language-conditioned behavior-cloning agent trained with supervised learning to detect actions. Instead of using object-detectors, instance-segmentors, or pose-estimators to represent a scene and then learning a policy, PerAct directly learns perceptual representations of actions conditioned on language goals. This action-centric approach with a unified observation and action space makes PerAct applicable to a broad range of tasks involving articulated objects, deformable objects, granular media, and even some non-prehensile interactions with tools.
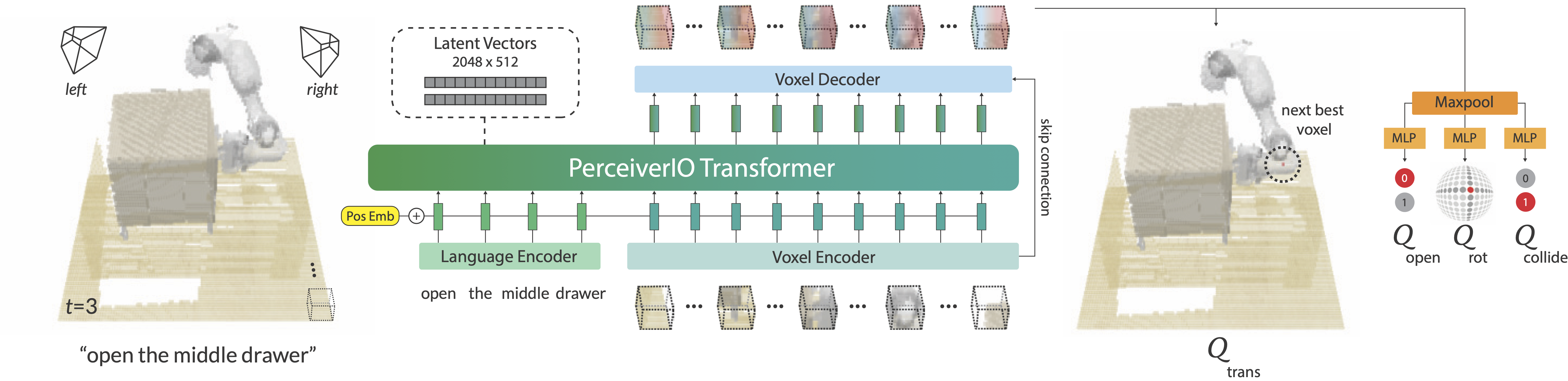
PerAct takes as input a language goal and a voxel grid reconstructed from RGB-D sensors. The voxels are split into 3D patches (like vision transformers split images into 2D patches), and the language goal is encoded with a pre-trained language model. The language and voxel features are appended together as a sequence and encoded with a PerceiverIO Transformer to learn per-voxel features. These features are then reshaped with linear layers to predict a discretized translation, rotation, gripper open, and collision avoidance action, which can be executed with a motion-planner. Overall, the voxelized observation and action space provides a strong structural prior for efficiently learning 6-DoF polices. Checkout our Colab Tutorial for an annotated guide on implemententing PerAct and training it from scratch on a single GPU.
Encoding High-Dimensional Input
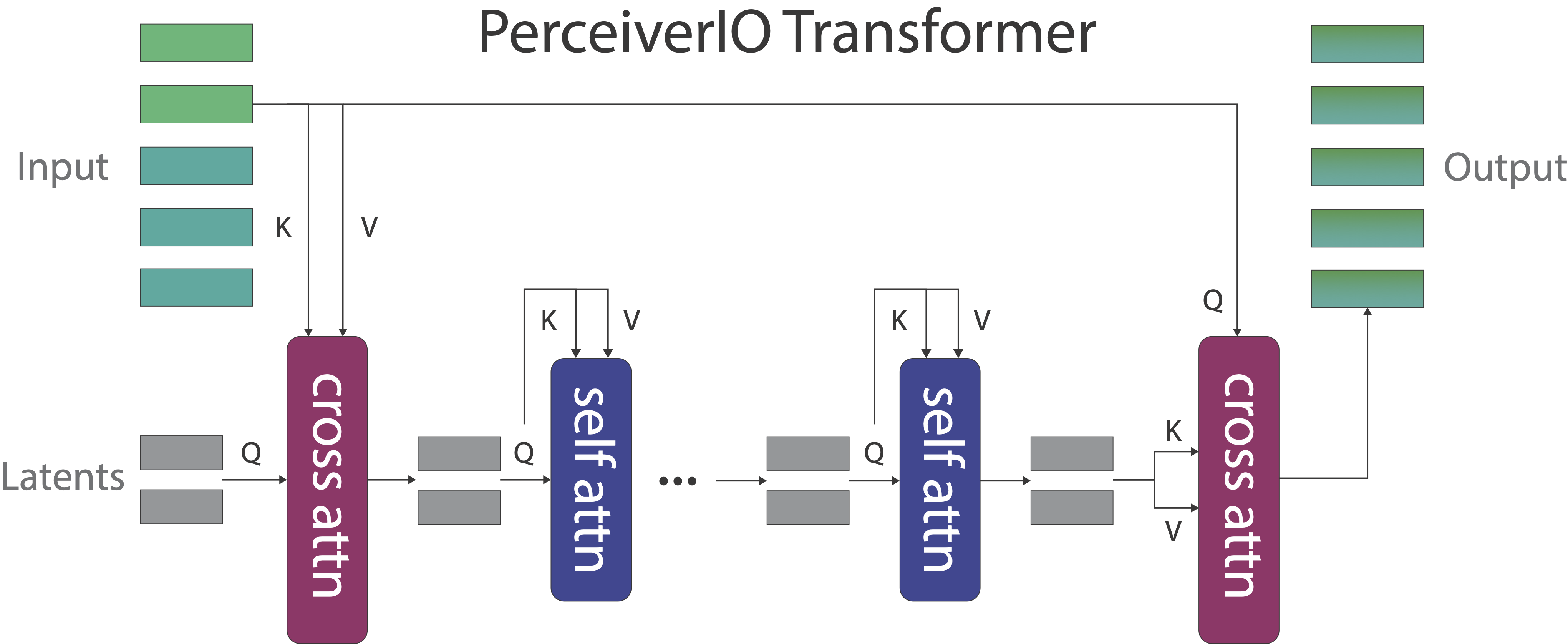 The input grid is 100×100×100 = 1 million voxels. After extracting 5×5×5 patches, the input is 20×20×20 = 8000 embeddings long. Despite this long sequence, Perceiver uses a small set of latent vectors to encode the input. These latent vectors are randomly initialized and trained end-to-end. This approach decouples the depth of the Transformer self-attention layers from the dimensionality of the input space, which allows us train PerAct on very large input voxel grids. Perceiver has been deployed in several domains like long-context auto-regressive generation, vision-language models for few-shot learning, image and audio classification, and optical flow prediction.
The input grid is 100×100×100 = 1 million voxels. After extracting 5×5×5 patches, the input is 20×20×20 = 8000 embeddings long. Despite this long sequence, Perceiver uses a small set of latent vectors to encode the input. These latent vectors are randomly initialized and trained end-to-end. This approach decouples the depth of the Transformer self-attention layers from the dimensionality of the input space, which allows us train PerAct on very large input voxel grids. Perceiver has been deployed in several domains like long-context auto-regressive generation, vision-language models for few-shot learning, image and audio classification, and optical flow prediction.
Results
Simulation Results
One Multi-Task Transformer
Trained withAction Predictions
Q-Prediction Examples
Visualize predictions forEmergent Properties
Tracking Objects
A selected example of tracking an unseen hand sanitizer instance with an agent that was trained on a single object with 5 "press the handsan" demos. Since PerAct focuses on actions, it doesn't need a complete representation of the bottle, and only has to predict where to press the sanitizer.BibTeX
@inproceedings{shridhar2022peract,
title = {Perceiver-Actor: A Multi-Task Transformer for Robotic Manipulation},
author = {Shridhar, Mohit and Manuelli, Lucas and Fox, Dieter},
booktitle = {Proceedings of the 6th Conference on Robot Learning (CoRL)},
year = {2022},
}